link layer
link layer는 인접한 nodes(host & router)끼리 연결하고 데이타그램 패킷을 프레임으로 encapsulate하는 역할을 한다.
링크 레이어는 인접 노드에게 물리적으로 데이타그램을 전송하기 때문에 요즘에 들어서 피지컬 레이어와의 구분은 따로 하지 않는다고 한다. 데이터그램이 전송되면서 각 링크별로 다른 프로토콜을 사용해 전송될 수 있다.(WiFi로 처음, 두 번째는 ethernet 같이)
링크 계층의 서비스모델을 자세히 보면 source와 destination에 대한 MAC 주소가 포함된 헤더와 에러 디텍션을 위한 트레일러를 포함해 encapsulate하고, 공유 매체에 접근할 수 있도록 한다. 여기서 MAC 주소는 링크 계층에서 노드를 식별하는 고유 주소, ip 주소는 네트워크 계층에서 노드를 식별하는 논리 주소임을 혼동하지 말자.

링크 계층은 또한 오류 검출 서비스를 제공한다. end-end에서도 오류 검출을 제공하지만 인접 노드간에 통신이기에 각 링크에서 발생하는 오류를 즉시 수정하면 효율이 높아 함께 사용한다.
물론 오류를 검출하면 correction하는 기능도 있고 인접 노드끼리 송수신 속도가 빠르지 않도록 흐름 제어 기능도 함께 제공한다.
링크 레이어는 모든 호스트에 설치되어 있는데 보통 네트워크 인터페이스 카드(NIC)에 설치되어 있다.
오류 검출의 경우 100% 신뢰할 수는 없지만 오류를 놓치는 경우가 매우 적다(rare)고 한다. 실제 검출 방식은 훨씬 더 복잡하다고 하지만 간단하게만 알아보자.
parity checking
single bit parity: d 길이의 비트가 있을 때 1의 개수를 짝수개에 맞추기 위해 마지막에 비트를 1 또는 0을 추가한다.
이를 좀 더 보완해 two-dimensional bit parity라는 col parity, row parity를 맞추는 방식이 나왔지만 거의 사용되지 않는다.

CRC(Cyclic Redundancy Check)
오류 감지에 방식중에 하나인 CRC이다. 위의 방식보다 더욱 강화되었다.
D: 전송하려는 데이터이다.
G: 오류를 감지하기 위한 r+1 크기의 bit 패턴으로 송신자와 수신자 모두 사전에 알고 있어야 하며 나눗셈을 수행한다.
R: 송신자가 추가하는 r 크기의 bit이다.
송신자와 수신자가 서로 통신하기 위한 일종의 key 값(CRC bit R)을 갖고 <D, R>의 비트를 XOR R 연산을 수행하여 나누어 떨어지지 않으면 오류를 감지하게 된다. 감지율도 높고 방식도 단순한 편에 속해서 현재 이더넷이나 WiFi에서 널리 사용되고 있다.
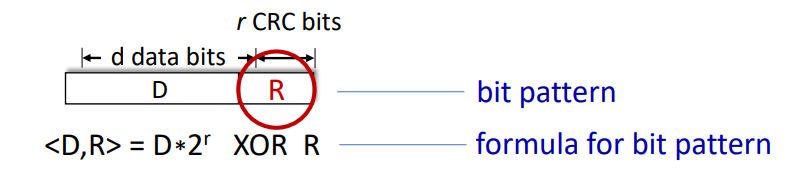
예시를 보자.
기존 데이터 D를 left로 r만큼 쉬프트한 값을 R과 XOR하여 n*G의 형태로 나와야 한다.
다시 말해 D* 2^r = n*G XOR R 이고, 이는 R = D*2^r / G의 나머지임을 알 수 있다.

기존 데이터 101110을 r=3 만큼 left shift 했고 이를 1001이라는 수신자와 미리 약속된 패턴으로 XOR하게 되면 R=011이 남게 된다. 그러면 송신자는 최종적으로 101110 011을 전송하게 된다!!
그렇다면 G는 어떻게 고를까? G는 비트 오류의 종류(길이)에 따라 다음과 같이 고려해서 선택하게 된다.
우선 단일 비트 오류(비트가 한 자리만 오류가 발생하는 경우)는 g(x)의 최고차항과 상수항이 1이면 오류난 한 자리만큼의 나머지가 발생하여 언제든지 검출이 가능할 것이다.
독립적인 두 비트 오류의 경우 E(x)=xi+xj의 꼴에서 xi(1+xj−i)로 묶을 수 있고 이는 곳 1+xt의 형태이기 때문에 1+xt의 형태만 피하면 모두 검출이 가능할 것이다.
다음으로 홀수 개의 비트 오류가 있는 경우는 g(x)가 (x+1)을 인수로 가지고 있으면 전부 검출이 가능하다. 이는 의외로 간단하다.
만약 홀수 개의 오류 비트가 있다고 가정하면, (x+1)로 나누어 떨어진다고 가정할 시 x=-1을 대입했을 때 0이 나와야 하지만 짝수개가 아닌 이상 어떤 방법으로도 0을 만들 수 없다. 즉 나누어떨어지지 않는다.
마지막으로 길이가 r+1(n-k+1) 미만의 어떤 비트 오류이던 검출이 가능하다!!
주로 쓰이는 CRC는 다음과 같다.

요는 첫 항과 상수항은 1, (x+1)을 인수로 갖고 있으며 (x^t+1)은 인수로 갖고 있지 않으면 된다.
Multiple access links, protocols
link에는 크게 두 종류가 있다. 이더넷 스위치와 호스트를 연결하는 point-to-point 링크와 모두가 공유하여 사용하는 broadcast이다. 그런데 broadcast에서는 여러 노드들이 한 채널을 동시에 사용하면 충돌이 발생할 수 있다. 따라서 이를 방지하기 위해 노드들끼리 채널을 공유하도록 도와주는 multiple access protocol이 존재한다.
R bps의 전송속도를 갖고 있는 채널의 이상적인 쉐어링 프로토콜은 어떤 프로토콜일까?
먼저 한 노드만 전송한다면 R bps의 속도를 그대로 사용할 수 있어야 할 것이다.
다음으로 M개의 노드들이 동시에 전송한다면 각각 동일한 전송속도인 R/M bps의 속도를 사용할 수 있어야 한다.
또한 어떤 노드도 특별 대우를 받아선 안되고(우선 전송권?을 갖게 한다던가) 각 노드들끼리의 슬롯이나 내장시계의 일치도 필요 없어야 한다. 일치하는 과정이 필요하면 그만큼 복잡해지니까(하지만 통신에 있어서는 모든 경우에 이 작업이 필요할 것이다.)
마지막으로, 단순해야 한다.
위의 목표들로부터 세 종류의 broad classes가 나왔다.
channel partitioning - TDMA & FDMA
TDMA는 time으로 슬롯을 나누어 각 슬롯의 사용권을 각 노드에 할당하는 방식이다.

FDMA는 frequency에 따라 채널을 나누어 나뉜 채널을 특정 노드에 할당하는 방식이다. 총 대역폭을 1/n으로 할당하여 사용한다.

각 노드별로 형평성이 높아진다는 장점이 있지만 고정적 할당이라 효율성을 높이기 힘들다는 단점이 있다.
위 방식은 주로 서킷 스위칭에서 사용된다.
random access
그래서 최대 효율을 위해 등장한 것이 random access이다. 요즘은 거의 패킷 스위칭을 사용하기에 가장 대중적이다. 위 방식은
충돌을 그냥 허용한다. 단, 충돌 시에 복구하는 기능을 갖췄다. 또한 노드별로 전송순서가 정해져있지 않고 그때그때 결정된다. 따라서 우리는 어떻게 전송 순서를 결정하고, 어떻게 충돌을 감지하며 어떻게 충돌을 복구하는지를 중심으로 살펴볼 예정이다.
random access - slotted ALOHA
slotted aloha에는 몇 가지 가정을 한다.
모든 프레임은 동일한 사이즈를 갖는다.
시간은 1프레임만큼의 동일사이즈의 슬롯으로 분할된다.
각 노드는 이 슬롯이 시작할 때에만 전송할 수 있다.
노드들끼리는 동기화되어있다.
만약 두 노드가 동시에 전송하여 충돌이 발생하면 모든 노드가 함께 감지한다.
작동방식은 다음과 같다.
노드가 전송할 프레임을 생성하면 다음 타임슬롯에서 전송한다.
만약 충돌을 감지하지 않으면 그 다음 슬롯에서 새로운 프레임을 전송할 수 있다.
충돌을 감지한다면 랜덤한 확률 p로 다음 슬롯에서 재전송을 시도한다. - 모든 노드가 다음 슬롯에서 전송을 시도하려고 하면 또 다시 충돌이 발생할 수 있기 때문에 랜덤한 확률로 전송하여 충돌을 회피한다.
slotted aloha는 단일 노드가 채널을 완전히 사용할 수 있고, 분산화된 방식으로 별도의 중앙 제어 장치가 필요하지 않으며 무엇보다 구현이 단순하다는 장점이 있다. 하지만 충돌이 자주 발생하면 슬롯이 자주 낭비되고 전송하려는 노드가 없으면 낭비되는 채널이 생기며 충돌을 감지하고 복구하기까지 시간이 필요하다는 점과 모든 노드가 clock 동기화가 필요하다는 단점이 있다.
사실 요즘은 사용을 안하는 방식이지만 향후 수학적인 성능평가 테크닉을 익히기 위해 알아두면 좋다고 한다.
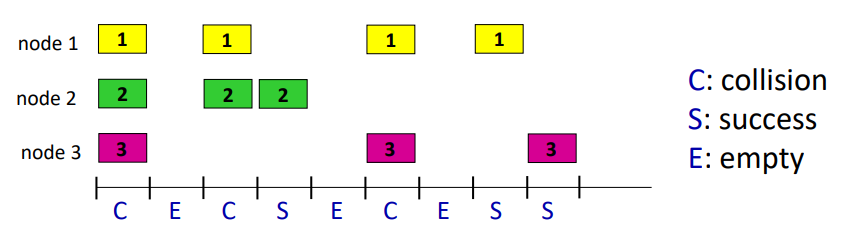
위에서는 3개의 노드만이 존재하여 대략적으로 1/3의 확률로 전송을 성공하지만 노드 수가 급격히 많아지면 충돌확률은 급격히 증가하고 전송확률은 매우 낮아질 것이다.
효율 예측을 해보자. N개의 노드가 p의 확률로 전송한다고 할 때
주어진 노드가 전송에 성공할 확률은 p(1-p)^(N-1)
아무 노드나 전송에 성공할 확률은 Np(1-p)^(N-1)
이다. p를 결정하기 위해 최대 효율을 내는 p를 찾으면 Np(1-p)^(N-1)을 미분하여 0이 되는 극대값을 찾으면 될 것이다.
구해보면 p* = 1/N이 나오고 p=1/e=약 0.37이 나온다고 한다. 따라서 최대 효율은 37%라는 얘기이다.

pure ALOHA
pure aloha는 slotted aloha에서 시간 분할이 빠진 모델로 노드끼리의 시간 동기화가 필요없어 더 단순하다는 장점이 있다. 따라서 프레임이 도착하면 노드는 즉시 전송을 시도하는데 각 노드들이 전송한 프레임끼리 조금도 겹쳐서는 안되므로 충돌 확률이 더 높아진다...;;
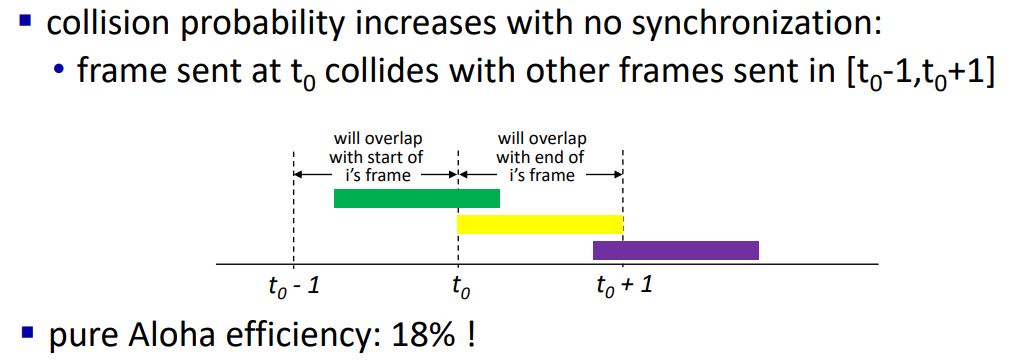
t0시점에 전송을 하려고 한다면 단순히 생각했을 때 먼저 전송을 시도한 t0-1시점의 다른 프레임과도 겹쳐서는 안되고 또한 전송이 완료되기 이전인 t0+1 시점에 다른 노드가 전송을 시도하여서도 안된다. 이를 수식화하면 p(1-p)^2(N-1)이 될 것이다.(앞 뒤로 다른 노드들이 전송하면 충돌이 나기 때문에 다른 노드들이 전송하지 않을 확률인 (1-p)^(N-1)을 두 번 곱해준다)
여기에서 최대 효율을 구하면 18%뿐이 안된다. time을 분할하는 이유는 이러한 효율 때문이다.
'cs > 데이터통신' 카테고리의 다른 글
| 802.11 WiFi 5, 6, 7 (0) | 2024.12.06 |
|---|---|
| CSMA와 이더넷 스위치 (1) | 2024.12.06 |
| Wireless and Mobile Networks (0) | 2024.12.04 |
| Physical layer: Signals (0) | 2024.12.02 |
| Network layer: control plane (1) | 2024.12.01 |